
Version: 0.0.9-SNAPSHOT
|
Linked Open Actors war ein frühes Konzept- und Spezifikationsvorhaben (2019–2022, NLnet-/FairSync-Kontext) zur Vernetzung von Akteuren des sozialökologischen Wandels über RDF/Linked Open Data. Aus dieser Arbeit entstand die Implementierung rdf-pub; die aktive Entwicklung wird heute im Nachfolger ChangingGraph fortgeführt – siehe https://changinggraph.org. Linked Open Actors was an early concept and specification effort (2019–2022, NLnet/FairSync context) to link actors of socio-ecological change via RDF/Linked Open Data. This work led to the rdf-pub implementation; active development continues in its successor, ChangingGraph – see https://changinggraph.org. |
Einleitung
Neben der Interessen der Wirtschaft etabliert sich eine verteilte Gemeinschaft von Menschen, die nicht an ein endloses Wachstum glaubt und versucht durch ein anderes Handeln einen sozialökologischen Wandel der Gesellschaft zu gestalten. Siehe auch Memorandum of Understanding des Wandelbündnis.
Um diesen Wandel sichtbar zu machen, ist es nötig die Organisationen des sozialökologischen Wandel zu vernetzen. Dazu werden Technologien verwendet wie das Resource Description Framework welche den Ansatz der Linked_Open_Data (LOD) ermöglichen.
Bekannte Datenquellen des LOD sind DBpedia und Wikidata. Es werden jedoch immer mehr, z.B. im öffentlichen Bereich GOVDATA.
Es soll kein weiterer zentraler Datenspeicher entstehen, sondern ein Standard der beschreibt wie Daten von Akteuren (Personen, Gruppen und Organisationen) des sozialökologischen Wandel präsentiert, gespeichert und ausgetauscht werden können.
Ein weiteres Hauptaugenmerk sind sogenannte Duplikate. Dabei handelt es sich um Akteure, die durch die Verteilung von Daten an mehreren Stellen gespeichert wurden und ggf. voneinander abweichen. Diese Daten technisch abzugleichen ist ein eher komplexes Thema, deshalb begnügen wir uns damit diese Duplikate zu markieren, so das man ihnen 'folgen' kann und nach ihnen suchen kann. Ein 'Datenbesitzer' hat dann die Möglichkeit diese Duplikate automatisch oder manuel aufzulösen.
Da sich der sozialökologische Wandel nicht auf den deutschsprachichen Raum begrenzt, wird die Spezifikation in Englisch verfasst. Zur Übersetzung von Texten wird DeepL empfohlen.
Introduction
A distributed community of people who do not believe in endless growth try to bring about socio-ecological change in society by acting differently. See also Memorandum of Understanding of Wandelbündnis.
In order to make this change visible, it is necessary to link the organisations of socio-ecological change. For this purpose, technologies such as the Resource Description Framework are used which enable the Linked_Open_Data (LOD) approach.
Well-known data sources of the LOD are DBpedia and Wikidata. However, there are more and more, e.g. in the public domain GOVDATA.
Another main focus is on so-called duplicates. These are actorss that have been stored in several places due to the distribution of data and may differ from each other. Matching this data technically is a rather complex issue, so we are content to mark these duplicates so that they can be 'followed' and searched for. A 'data owner' then has the option of resolving these duplicates automatically or manually.
Situation Today
There are a lot of smaller and bigger plattforms, that provide data about other Actors to different topics in different formats.
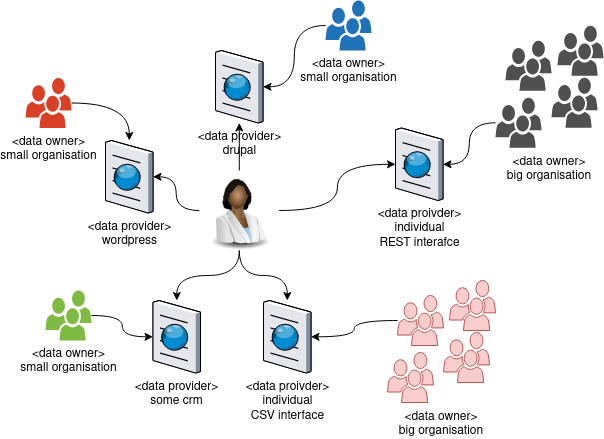
What‘s the Problem ?
-
Users have to search at many different web sites providing data on similar issues.
-
Hard work for search engines to indicate and present the data.
-
Impossible to share agents between data providers (especially for small agents).
-
It is not possible to mark agents/events as „sameAs“ (if two or more data provider share the same agents)
-
Almost no way to use the agent/event information in services or at other web sites.
Conclusion
-
Users do not find the agents/events they are searching for.
-
There is no way to search agents/events across data providers and no easy way to filter by specific criteria.
What is our plan ?
-
After a lot of research, we had decided to use the Resource Description Framework (RDF) to describe the data (agents/events).
-
We work on a RDF Schema. Based on ISA² Core Vocabularies of the European Commission.
-
We work on a prototype providing /using data from three different agents.
Potential RDF partners
We are currently protoyping and discussing how to implement RDF adapters for a distributed linked data store for
* https://incommon.cc
* https://kartevonmorgen.org
* https://wechange.de
* https://openengiadina.net
* GLS futopolis
* Ecosia search engine
* Economy of the Common Good
Architectural Overview
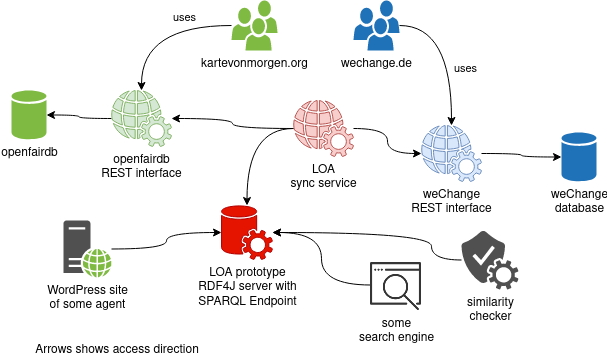
-
We do a initial load of data from WECHANGE (WE) & KartevonMorgen.org (KVM) to a RDF4J server.
-
WE & KVM are bigger organisations and are able to provide a REST endpoint, that the LOA sync service can use for keeping the RDF4J server up to date.
-
WE & KVM provide some endpoint to mark an agent with „sameAs“ (process therefore is in discussion)
-
RDF4J Server provides the SPARQL protocol and a RDF Query Language (SPARQL) endpoint
-
On the diagram above you might get the impression that the LOA RDF server in the middle is a central location.
-
This is not the case, everyone can provide an RDF/SPARQL server. We expect that larger organizations provide their own RDF server.
-
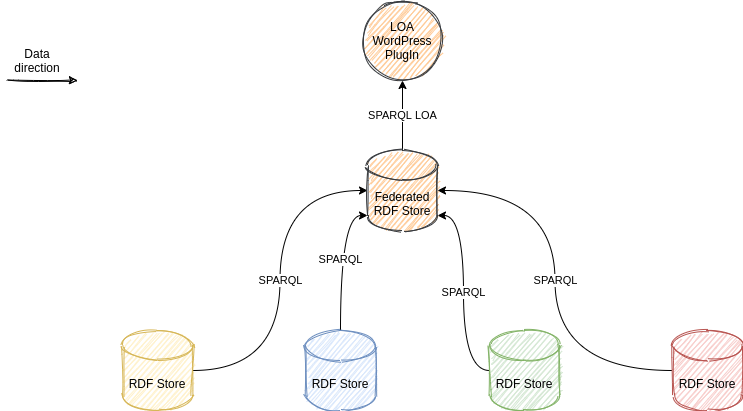
Search across different RDF servers can be done with federated queries.
Federated Queries
-
A RDF server can integrate SPARQL endpoints of other providers as a proxy.
-
Then the queries can be executed over different RDF Servers.
-
Sample: LOA RDF4J Server defines a proxy for dbpedia.org. → An agent from KVM extended by dbpedia data can be queried. (Provided that data of this agent is available in both servers.)
Introduction to the concepts
Short version
-
For a generel introduction on What is Linked Data? see Manu Sporny’s Introduction it’s about 12 minutes.
-
For the concept of URI, URL, Namespaces and Prefix (in this video called CURIE) see RDFa Basics from 1:25 to 2:23
-
a longer detailed description about URIs How to name Things URIs about 20 minutes
-
A introduction about RDF 1.7 How to Represent Simple Facts with RDF from 3:16 to 10:02
-
The turtle format explained RDF and Turtle Serialization about 14 minutes
Expert version
-
About RDF4J we will use RDF4J Server and Workbench as Triple Store and SPARQL Endpoint.
Specification
Since Mai 2021 the specification is a separate project with it’s own release cycle.
Adapters
Karte von Morgen (KVM)
This is the description of the integration of the early adopter "Karte von Morgen" (KVM).
Supported UseCases
-
Create LOA Data not supported! Data creation has to be done via the openfairdb REST Service.
-
Read LOA Data by IRI not supported (Feb. 2021, maybe later)
-
Update LOA Data by IRI not supported! Modify data has to be done via the openfairdb REST Service.
-
Delete LOA Data by IRI not supported! Deleting data has to be done via the openfairdb REST Service.
-
Query LOA Data by SPARQL SPARQL Endpoint
Adapter
The adapter is regularly triggered by a the loa app
Prototyping
RDF Server & SPARQL Endpoint
-
We are using a RDF4J Server and Workbench instance which is acessible here
-
Currently (1.4.2021) the newest kvm data is in this repository
-
There are also some sample Queries
The LOA app
For prototyping we also need some adapters, that for example provide the KVM Data as RDF and provide a SPARQL Endpoint for WECHAMGE & KVM. Therefore we implement and host a web app called LOA-app. You can browse the code.
Demo Setup Juni 2021
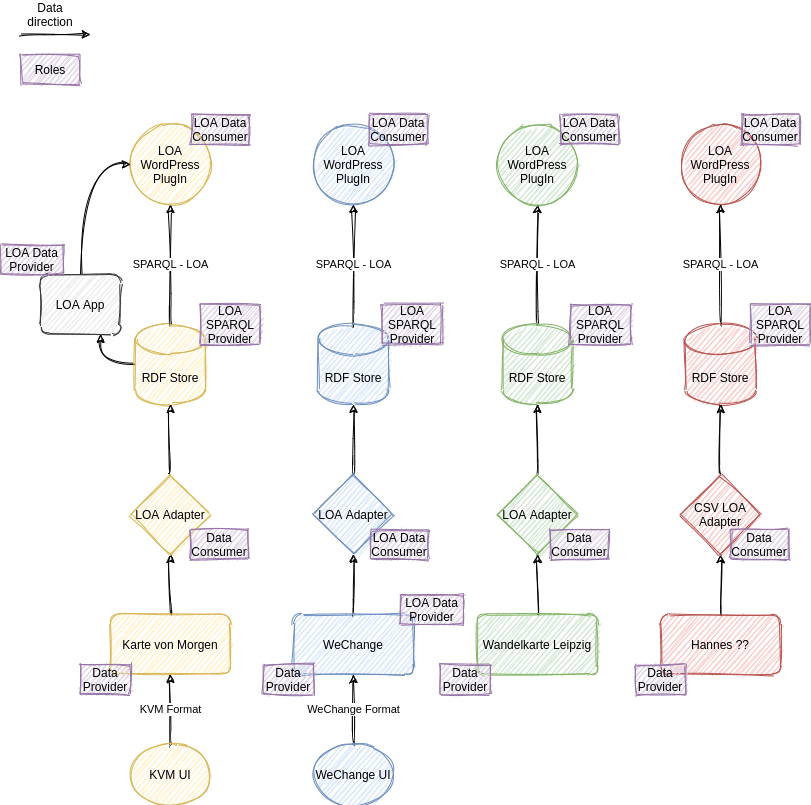
As of June 2021, we have 4 data sources ("Data Providers") and one of them even speaks LOA already and is therefore a "LOA Data Provider".
Because no one of the "Data Providers" can provide a SPARQL endpoint until now, we provide LOA Adapters for each of them. All expect the
csv adapter (red one) poll for changes at the data provider and keep the data in the RDF Store up to date.
The csv Adapter for now is for testing purpose, first and foremost, we want to make comparisons here and test algorithms and comparators.
Because Karte von Morgen is not a "LOA Data Provider" we provide a LOA-App, where the kvm data can be read in LOA Format.
That is not necessary for WeChange, because they already provide single Publications/Organisations in LOA Format.
The RDF Stores are a RDF4J-Workbench with a RDF4J-Server running on a fairsync Kubernetes cluster. The LOA-App is a Spring-Boot (reactive stack) app, that is running on a Open Source Ecologie Server (https://www.ose-germany.de) administered by our m4h (https://www.m4h.network/) friend.
Experimental
The categorie model
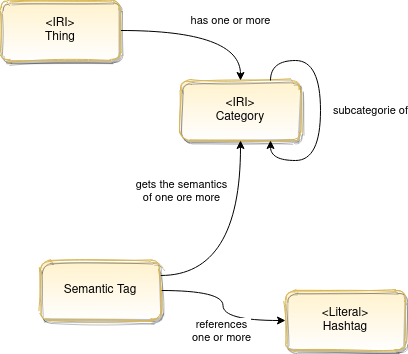
Explanation
Some "old" thoughts. In the meanwhile we think SKOS will be our solution.
Thing
Thing is synonymous for Object. Describes an object of any kind. The Object type serves as the base type for all Entities.
Hashtag
A hashtag is a word or a string of words preceded by a hash sign, i.e. a double cross (#). A hashtag is used for communication within platforms, such as Map of Tomorrow, WeChange, ecogood. Users of a platform can tag agents with the hashtag (e.g. #direktvermarkter), which makes them clickable for other users. A click on such a hashtag would then lead to an overview page or map, which would then bundle all agents that have been tagged by users with this hashtag.
Categorie
-
The categories can have a tree structure. this is represented by the relationship "subcategory of".
Semantic Tag
Users should be able to tag things as easily as possible. This should be possible without having to deal with a certain categorisation or having to read into anything. To give moderators the possibility to assign "wild user tags" to categories, we use semantic tags. For example, if we have taggs like "eco good", "ecogood", "gwö", "gemeinwohl ökonomie", a moderator can assign all these taggs to a semantic tag and assign this semantic tag to one or more categories.
About
This is an activity of the fairsync project, funded by NLnet.
Team
Fred Hauschel
Software Engineer
https://hauschel.de
Roland Alton
Communication Engineer
https://roland.alton.at
Open Issues
To be discussed
Opening OpeningHoursSpecification
In the [Core Public Service Vocabulary Application Profile 2.2.1](https://joinup.ec.europa.eu/collection/semantic-interoperability-community-semic/solution/core-public-service-vocabulary-application-profile/release/221)
The opening Hour specification of schema.org is used. the pdf is available [here](https://github.com/catalogue-of-services-isa/CPSV-AP/raw/master/releases/2.2.1/SC2015DI07446_D02.02_CPSV-AP-2.2.1_v1.00.pdf) See 3.12.5. Opening Hours.
The OpeningHoursSpecification of [goodrelations](http://www.heppnetz.de/ontologies/goodrelations/v1.html#OpeningHoursSpecification) is also very simmilar to the [schema.org OpeningHoursSpecification](https://schema.org/OpeningHoursSpecification)
The [openstreetmap format](https://wiki.openstreetmap.org/wiki/Key:opening_hours) currently used by karte von morgen differs in format.
TODO: we have to discuss and decide how we solve that. A feew weeks ago we decided to postpone that decision and did not support openingHous in the first version.
category/tag
https://www.w3.org/TR/vcard-rdf/#d4e813 Bei KVM steckt semantik hinter manchen tags, diese sollte man auflösen!
Sample Entry
@prefix fairsync: <http://fairsync.naturzukunft.de/> .
@prefix person: <http://www.w3.org/ns/person#> .
@prefix schema: <https://schema.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix locn: <http://www.w3.org/ns/locn#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
fairsync:12912983213423098721430ss40569 a foaf:Group;
dcterms:Location fairsync:12912983213423098721430ss40569_location;
schema:ContactPoint fairsync:12912983213423098721430ss40569_contactPoint;
dcterms:identifier "12912983213423098721430ß40569";
foaf:name "Mutsreman GmbH & Ko KG";
foaf:homepage "http://example.org";
owl:versionInfo "3";
dcterms:description "This is a sample description of this sample organisation!";
schema:foundingDate "2015-01-02" .
fairsync:12912983213423098721430ss40569_location a dcterms:Location;
locn:Geometry fairsync:12912983213423098721430ss40569_geometry;
locn:Address fairsync:12912983213423098721430ss40569_address .
fairsync:12912983213423098721430ss40569_geometry a locn:Geometry;
schema:latitude 4.669561163368431E1;
schema:longitude 7.619049236001004E0 .
fairsync:12912983213423098721430ss40569_address a locn:Address;
locn:postCode "82633";
locn:adminUnitL1 "Germany";
locn:adminUnitL2 "BW";
locn:postName "München";
locn:addressArea "KluedoStrasse 12" .
fairsync:12912983213423098721430ss40569_contactPoint a schema:ContactPoint;
schema:name "Mr. Mustermann";
schema:email "max@mustremann.de";
schema:telephone "089 62899835" .Integrating Karte von morgen
OpenFairDB adapting

-
OpenFairDb has to provide an endpoint for each Resource responding with text/turtle.
-
OpenFairDb has to implement a single load of all data to the RDF4J Server (using REST API)
-
OpenFairDb has to take care, that the data iin the RDF4J Server is upToDate (using REST API)
-
To be clarified: Are there some restrictions for Using SPARQL with that Adapter?
-
Sure, it’s not possible to use manipulating SPARQL queries. Attention: Can we be sure, that nobody is using it?
Exteral adapter

-
external service has to provide an endpoint for each Resource responding with text/turtle.
-
external service has to implement a single load of all data to the RDF4J Server (using REST API)
-
external service has to take care, that the data iin the RDF4J Server is upToDate (using REST API)
-
external service has to communicate with openFairDB to keep syncronized (listening/polling)
-
To be clarified: Are there some restrictions for Using SPARQL with that Adapter?
-
Sure, it’s not possible to use manipulating SPARQL queries. Attention: Can we be sure, that nobody is using it?
Database replacement

-
OpenFairDb has to replace it’s database with a RDF4J Server (or another SPARQL supporting triple store)
-
Self hosted or RDF4J as a service